
市场上空间定位的技术方案分为单目、双目以及激光雷达三大阵营,其中激光雷达由于成本高昂市场接受度较低,而在都是基于计算机视觉的单目和双目中,双目则显得更受欢迎。在国内做计算机视觉技术方案的企业如图漾、速感、人加智能等大多选择了双目,而选择了单目的欢创科技则成为了少数派。那么,双目为何比单目更受市场青睐,两者之间的技术差异在哪里,单目又是如何实现空间定位与追踪?本期雷锋网硬创公开课邀请到欢创科技CEO周琨,详细单目定位技术。

周琨,大学深圳研究生院硕士生导师,深圳市高层次人才,南山区领航人才,深圳市欢创科技有限公司CEO,大学本科、硕士,师从973首席科学家,长江学者戴琼海教授。十余年IT和人机交互技术行业产品研发和技术管理经验。先后就职于贝尔实验室,中国移动,对视觉人机交互技术进行了非常深入的研究,作为主要发明人,拥有二十余项国际和国家专利,并先后获得科技进步二等和深圳市科学技术专利。2014年初创办欢创科技,担任CEO职位,引领公司致力于计算机视觉空间定位与追踪技术的研究和产业化,目前产品已经广泛应用于电视机、VR与机器人领域。
以下为嘉宾分享内容实录。相对视频文中做了删减,完整内容可观看视频。关注雷锋网旗下微信号「新智造」,回复「PPT」可获取嘉宾完整PPT。
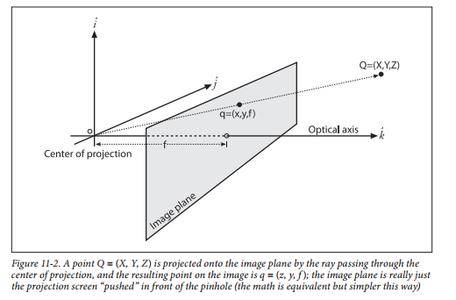
从工程意义上来说,测量一个物体相对于另一个物体的与姿态,即所谓的位姿测量。从数学意义上来讲,测量两个坐标系间的平移与旋转变换关系,包括3个(Translational)和3个旋转角(Rotational)共6个位姿量(即6DOF)。理论上,只要已知空间不共线点在两个坐标系下的坐标,就能唯一确定两坐标系间的位姿关系,因此,位姿测量的关键就是如何得到特征点在这两个坐标系下的坐标。

自定位(inside-out),即通过相机拍摄视野坐标系,以及坐标系的特征点,从而判断相机相对坐标系自身的坐标。比如我们常用的SLAM,这方面雷锋网之前也有嘉宾做过介绍,它的特点是便携、视角理论无限大、定位精度不高。主要应用领域包括移动机器人、无人机、VR、AR。

外定位(outside-in),比较常见的是OptiTrack,特点是安装复杂、视角有限、定位精度高。主要应用领域包括影视动捕、VR、工业机器人。

特点:系统复杂,运算量大,可以单帧单目标点定位,对目标物体无几何约束,,应用场合灵活,成本较高。
目前关于双目定位的研究与市场应用相对比较多,而单目定位则相对比较少,所以,今天我就重点讲下单目定位。
顾名思义,单目视觉定位就是仅利用一台摄像机完成定位工作。单目视觉定位的方法主要有两种:基于单帧图像的定位方法和基于两帧或多帧的定位方法。
基于单帧图像的定位方法包括基于特征点的定位(Perspective-n-Point)、基于直线特征的定位,关键点在于快速准确地实现模板与投影图像之间的特征匹配。
P-n-P,即Perspective-n-Points,指给定世界(刚体)坐标系下的n个3d坐标点,以及这些点在图像中的2d投影坐标,求解世界(刚体)相对相机的姿态和(求解R,t)。要想求解出世界(刚体)相对相机的姿态和,必须知道至少4个点,也就是n要大于等于4,当然这是必要条件,不是充分条件,充分必要条件是n等于6。
双目视觉定位原理是指通过三角测量原理来对目标点的三维空间进行定位。双目视觉定位的算法流程:相机标定、双目标定、图像处理、特征检测、立体匹配、三维测量、姿态测量。
单目视觉有效视场更大:刚体定位不仅不依赖多个相机,定位空间还可以通过多个相机进行扩展而不发生视场范围损失。
定位方式:手柄和头盔通过无线控制红外定位点发光时间与摄像头时间同步;PC使用从图像获得的定位点信息与IMU数据融合,获得头盔和手柄的信息。
缺陷:覆盖范围比HTC小,达到roomscale需要更多的定位器;所有定位信息统一计算,不利于扩展到多人或更多设备。

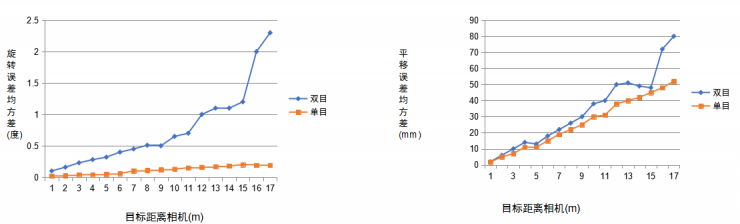
周琨:从定位精度和鲁棒性来说,双目还是比单目好一些,如果从单目的场景来说,物体的复杂性会更高,而且单目的成本更低,但是对于机器人来说,成本不是太大问题,所以用双目做机器人的移动避障会更好些。
周琨:ADAS我研究的不多,我就以我认知的来说下。因为汽车是高速移动的物体,所以ADAS的反应速度非常快,单目的好处是视角范围比较大,双目的局限就在于它的视角会受限,不过单目只有一只“眼睛”,3D定位的话尺度问题不好解决,双目的定位范围要大些,精度可以做的比较高些。所以说两者之间还是有差别的。
周琨:目前主要是两个方向,一个是SLAM,这个常大的研究方向,不过到现在其实都不太成熟,到目前为止我见过最成熟的产品就是微软的HoloLens,就是有很多摄像头才能做到鲁棒性比较好,闭环做的比较好,无论是tango还是高通在VR上的的SLAM,都容易受到欢迎因素的影响,包括光照、白墙等等,离实用还是有比较大的距离,所以说这是一个比较大的研究方向。
第二个就是在工业应用领域,这个时候需要解决的问题是精度,也就是说不用考虑成本问题,研究方向就是如何提高精度,毫米不够就亚毫米。
周琨:在工业机器人领域,视觉应用会越来越广泛,比如仓储机器人都是无人值守的,自己完成搬运工作,那么它需要“眼睛”来识别,目前比较常见的定位方案是Kiva的标记点,未来一定是使用SLAM方案,机器人可以自行规划线;第二个场景是制造,虽然说机械臂可以进行定位,但是仅适用于大批量重复性的制造,如果你需要经常对这个加工的目标不停的改变,你就需要辅助定位装置帮你进行重新设定,这个时候它的优势就出来了。
周琨:实际上现在我们常见的应用都会加入多个传感器来获得摄像头的位姿,最常见的就是MU,六轴或九轴的传感器辅助获得摄像头的位姿,比如摄像头出现遮挡,往往需要MU辅助获得摄像头的位姿,还有一种假如在室外,通过GPS获得经纬度,通过气压计获得高度信息,其实这也是多传感器融合的情况。
新智造:在图像采集完后对图像处理,放大目标图像的灰度值,缩小非目标的灰度值中,如何使这个比例能更协调,而不只是根据主观推断?
周琨:根据我们的经验比较难做,因为很难区分目标与非目标,所以我们常见的做法是尽可能在原始数据时让目标与非目标的区分度更大一些,方法很多,比如说可以通过增大目标物体的特征,比如亮度,或者通过调制光,把目标的特征点与非目标的特征点放大,然后再去放大灰度值,就是第一步就把问题解决,就很容易区分目标与非目标。所以,我倾向于解决问题解决前面,而不是放到后面去解决,这样会很难的。
周琨:最笨的方法是提高相机的分辨率,很容易把目标的像素点提高,获得的信息就多了,特征点容易稳定,带来的坏处就是增加成本,如果在不增加成本的情况下获取稳定的特征点呢?其实我们也做了一些工作,就像PPT里讲的做到了亚亚像素的精度,采用的策略是尽可能采集样本的数量,带来的坏处就是可能数据量增加帧数会下降,那么如何在样本数量增加的同时保障帧数不下降,这个是需要解决的问题,但是方法无外乎就是这些!
周琨:图像匹配过程中首先要找特征点,要想提高匹配精度就要尽可能找出更多的特征点。无论是双目还是单目,最难的场景是面对一面白墙,没有任何特征点,这个时候要想提高匹配精度就很难,这个也是一个世界难题,目前就我所知还没有特别好的办法能解决,如果非要去解决,那就人为制造特征点,比如打散斑,也就是结构光,这个时候能够提高匹配精度。简单来说就是尽量找特征,没有特征的话就人为制造特征。
周琨:如果你用CMOS传感器它就比较容易实现,因为好多CMOS传感器都有时间戳同步功能,如果CMOS传感器你还需要用到MU,想要实现时间戳同步,就需要确定一个同步的中心元,像在VR里面,比如我有两个摄像机和手柄,这个时候你需要用头盔做这个同步的中心,它发射命令出来,所有摄像头也好手柄也好向它对齐,关键是做到这一步,其他方面我觉得没什么。返回搜狐,查看更多
推荐:


 删除。
删除。
网友评论 ()条 查看